Talk:Definitions
This is a summarisation from the discussion Abdul and Marcus had in private mail exchange.
Contents |
Challenge
Marcus: "A challenge is every kind of input to the system including every single bit or environmental impacts. Most inputs have been forseen by the system designer and are handled correctly by the system. All other inputs have the potential to trigger dormant faults which are inherently in the system. Defensive measures prevents that some of these inputs really trigger the dormant fault and thereby preventing the fault from becoming an error."
Abdul: "Well, I do not like the idea that every data bit is a challenge to the network. Instead, I propose that we say that challenges can trigger dormant faults but are not the only means of triggering dormant faults. Some dormant faults can be triggered by time, data traffic, age. This will fit in fine with the existing literature on faults where terms like mean time between failures (MTBF) is used to say that after so may years, the components may fail due to prolonged use (basically AGE of the equipment). I don't think that categorizing time/aging as a challenge is a good formulation."
Abdul's definition proposal: "A challenge, then can be something that exploits an existing vulnerability (dormant fault) in the system to cause a (active) fault but is not the only triggering mechanism."
Marcus: "I admit that i.e. aging should not be part of the challenge definition."
CFEF state transition
Proposals for the "Challenge-Fault-Error-Failure" state transition diagramm have been made by [ULanc] and [KU].
{kind=link}
Originally, the transition diagram of ULanc, reworked by KU is shown below. This is currently the favorite...do I hear an objection to this contender? The power point of this picture is available here for your tinkering.
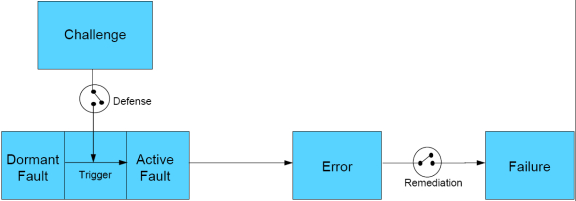
An open question remains: What does prevent an error becoming a failure? Is it an other part of "Defense" or is it "Remediation"? How does our "self-containment" principle play into this?
Marcus: Looking at the definition of Challenge covers everything we have thought of so far which can trigger a fault to become active. This would mean that our picture is complete now. Unresolved is the definition of Threat.
Abdul: We should work out a couple of example in complete detail to see it this formulation holds up. We can continue on the example that is given below.
Marcus: Remediate would require a backlink from Failure to Error with a 'maybe' attached. In some cases remediation can make an failure disappear, i.e. not longer visible to the service consumer, becoming an error again.
Abdul We need to clarify the distinction between the network being in error state and providing full services and network being in normal state providing full services. One is remediation and other is recovery.
Examples on Error to Failure transition
- A router fails due to an interface problem but the forwarding service can be maintained if we have a hot stand-by router taking over the service seamlessly (e.g. VRRP). This means that the service does not experience any changes of the delivered service although the error persits. We can derive a transition from 'Error' to ' Normal Service Operation'. A defensive measure prevented the 'Error' from becoming a 'failure'.
- A router fails due to an interface problem. If no alternative path exist the 'Error' becomes a 'Failure' and the service will remain in 'Service Failure' state. No 'Defense' against this error was implemented.
- A router fails due to an interface problem but the routing protocol selects a new forwarding path. The routing protocol must "Detect" the failure to trigger the recalculation of forwarding paths.
- The service temporarily fails until the new route is selected. This is an example for the transition from 'Error' to 'Service Failure'. Our defense has failed.
- The selection of a different path by the routing protocol is a transition from 'Service Failure' to ' Normal Service Operation'. I label this transition with "Remediation".
- A node experience a flow completeness failure due to bit flips on a noisy channel. On "Detection" of the cause the node activates an ARQ mechanism.
- Until activation the service fails since packets get dropped. Making the 'Error' becoming a 'Failure'. Again, our defense has failed.
- After activation still packets are dropped but retransmitted. The service can fulfil its task but with reduced performance. This indicates a transition from 'Service Failure' to 'Partially Degraded Service'. This is again "Remediation".
- An E2E connection can experience packet failure due to packet drops on a congested router on the path. An ARQ mechanism like retransmission prevents the service from failing but degrades the service performance. This is a transition from 'Error' to 'Partially Degraded Service'.
I refined the above picture to show the new states and transitions. The source to the picture in PPT-Format can be found here.
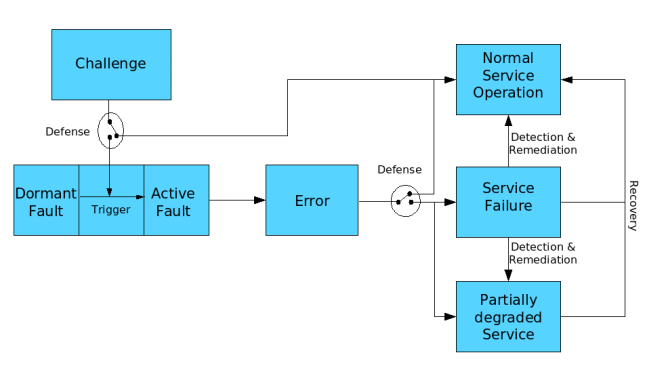
The term 'partially degraded' was introduced by Abdul in his ICNP paper which I have adopted here.
'Recovery' means that the cause of an error is deleted and the service can return from 'Service Failure' or 'Partially Degraded Service' to 'Normal Service Operation'. 'Refine' can not be shown in the diagram because refinement will change the overall system: deleting faults, introducing new ones, and adding new defensive measures, detection mechanisms, and remediation features.
Challenges revisited
Marcus: I was thinking a little more about our definition of challenge and its relation to the picture above. So far we only looked at the removal part of challenge: destruction of node or link, channel interference, attacks, etc. But what about addition of something? Is the integration of a new node to a wireless ad-hoc network not a challenge for the network?
Again the state of the system after the addition of something depends on the service description. I try to give an example: A P2P document service can be described as follows: the pointers to the documents should be equally distributed among the peers. If we add a node to the P2P network the distribution is not equal any longer. The network starts a process to get the distribution right again and moves some of the pointers to the new node. This process is something very much like the remediation or recovery process of our D2R3 strategy.
The question which arises: Are 'Errors' the only source to change the system state from 'Normal Operation' to 'Partially degraded' or 'Service Failure' or are there other sources? If there are other sources, how are they called?
Abdul: I understand your concern with the definition of a challenge. However, we have to be very careful how we include the addition part in the definition of a challenge. In my opinion, we cannot classify every event that changes the STATE of the network as a challenge. I DO NOT think that addition of a new ad-hoc node is a challenge to the wireless network. In this case, we are basically changing the (physical) characteristics of the network thereby changing the operational state of the network....resulting in the change of the performance. If we were to go down this lane, then by construction the system/network can have only one operational state and everything else will be a challenge.
The P2P pointer distribution example is a very compelling one. However, I feel that no service definition can be absolute in nature. So is the case with network service level agreements. For example the delay of a network may be guaranteed to be with in a min and max value. If one were to specify an absolute delay value, then every addition and subtraction of a data flow through the network would change the delay and the network would have to take corrective action. Hence, given the dynamic nature of the P2P network, having an absolute service description would be a poor design. In summary, service descriptions must always have room to accomodate inevitable transients and should also have room for differentiated services (multiple service states) as well.
Please feel free to punch holes in my argument.
Marcus: I agree. Especially the flow example shows that the addition of something is different from the challenges we considered so far. But what about route flapping? The constant removal and addition leads to an instability in the routing protocol. In this scenario the addition is part of triggering a fault - namely not to be resistant against instable links. The distinction does not seem to be that easy to me.
Are faults service independent
Marcus: " I hope the following example proofs my statement of an error being independent of the service description:
Let me give you two services: the first is a IP based transport service, the second is a transport based on DAB. If we have a noisy channel some bits could flip during transmission. Such a bit flip is a fault, since the data sent out and the data transfered are different. For the IP based service this would lead to a packet failure since it can only drop it. For the DAB based service this is not necessarily a packet failure due to the feature of using an forward error correction code. It can correct some bit errors per packet. If the error depends on the service description, too, we would see no error at all for the DAB based service which would include that no fault has occurred.
Abdul derived tables for this examples:
| Phenomenon | Instance | Occurred/exists/did not occur | Why (reason) | additional remarks |
|---|---|---|---|---|
| Dormant fault | use of wireless channel | exists | ||
| Challenge | noisy channel | exists | environmental challenge | |
| Active fault | bit flip (bit error) | occurred | no defense against challenge | |
| Error | packet loss (drop) | occurred | a fault will cause an error | |
| Failure | end-to-end transport service | did not occur | system is designed to handle packet errors through retransmissions |
| Phenomenon | Instance | Occurred/exists/did not occur | Why (reason) | additional remarks |
|---|---|---|---|---|
| Dormant fault | use of wireless channel | exists | ||
| Challenge | noisy channel | exists | environmental challenge | |
| Active fault | bit flip (bit error) | occurred | no defense against challenge | |
| Error | packet loss (drop) | does not always occurr | forward error correction code reverses bit flips | |
| Failure | end-to-end transport service | did not occur | no errors |