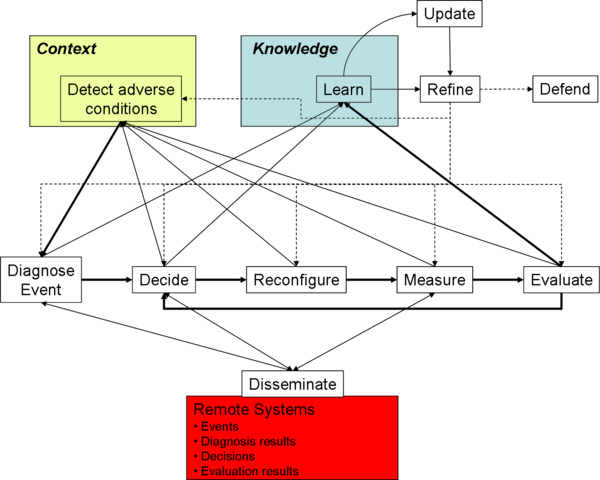
Talk:ResiliNets Strategy
Contents |
S1. Defend
The first step in the resilience strategy is to defend against challenges and threats to normal operation. The goals are to
- reduce the impact of an adverse event or condition
- reduce the probability of an error leading to a failure
A threat analysis is necessary to mount a defence.
Tasks
Self-Protection
- DoS Resistance: All service must be protected from DoS attacks. One crucial aspect of this is state management. If a service needs to set up state it must not do so without verifying the communication peer. A creation of state after a successful verification of the communication peer can be achieved by stateless cookies or cryptographic puzzles.
- Trustworthy signalling protocols: Control plane protocols a crucial the correct operation of the network. To protect users from malicious operation others the data of all signalling protocols has to be authenticated and integrity-protected.
- Cache consistency: Caching of resolved information speeds up later resolution procedures but can suffer from cache poising attacks. Only information which can be verified should be cached.
- Firewalling: Block illegal traffic on the end systems or within the network. Firewall rules can be adjusted dynamically in the case of adverse conditions.
- Traffic shaping: Rate limitation, burst dampening and other mechanisms can be used to protect guarantees given to users. Parameters can be adjusted dynamically in the case of adverse conditions.
Redundancy and Diversity
- Hot Stand-by: Redundant service instances can be used to switch fast from a failing instance to a correctly running one. If operational diverse service instances are used the robustness to challenges also increases.
- Load Balancing: The replication of service instances and the balancing of their load helps to cope with large numbers of service requests. Deployed correctly the failure of one instance can be transparently masked to the service consumer as can new instances added without any changes to the service consumer.
- Voting protocols: To make the result of a service request more reliable voting protocols among diverse service instances can be used. Thereby, erroneous results from a minority of service instances can be masked to the service consumer.
- Use operational diversity to make the system resilient to faults. It is unlikely that different implementations are vulnerable to the same trigger cause an fault to become active.
Containment
If a service detects an erroneous condition it should mask it to the service consumer whenever possible. If the service can not recover from this state on its own it must return a meaningful error report to the service consumer.
Related Principles
- P3. Threat and Challenge Models
- P10. Redundancy
- P11. Diversity
- P13. Security and Self-Protection
- P14. State Management
Examples of defences
- erasure coding over spatially redundant diverse paths, which permits data transfer to continue even when one of the paths is disrupted
- secure signalling protocols with necessary authentication and encryption to resist traffic analysis and prevent the injection of bogus signalling messages
Remarks
S2. Detect
The second step is to detect when an adverse event or condition has occurred. This includes detection of:
- Challenges threatening the system
- Errors within the service and
- Failures of lower level services
Detection is used to determine when
- defences need to be strengthened
- defences have failed and remediation needs to occur
- fault diagnosis has to be started
Tasks
Detect challenges
- Detect attacks
- Anomaly based attack detection
- Signature based attack detection
- Detect anomalies
- Detect service errors
- Detect service failures
- Detect environmental changes
- Connect and disconnect events
- Service crashes, service misbehaviour
- Interference on wireless medium
- Congestion on next hop
- Distributed detection
- Exchange incident information
- Voting to identify misbehaving entities
- Coordination of detection instances
Detect end-of-challenge
To detect the end of a challenge can be more difficult than the start of a challenge. In very simple cases like a link break the end is detected very easily. But if the challenge was congestion on the next hop and the system re-routed some of the traffic as a remediation action the decision that the challenge - the huge amount of traffic - is over can not easily determined.
Triggers
- Strengthen defence???
- Remediate system operation
- Diagnose root cause
Related Principles
- P1. Service Requirements
- P2. Normal Behaviour
- P3. Threat and Challenge Models
- P4. Metrics
- P8. Translucency
- P16. Context Awareness
Remarks
Marcus: Again can we add examples, like self-monitoring on the hardware level, the application level and the protocol level. So far the subsection does not say too much about detection in contradiction to the title. Maybe we should link to 'monitoring' in this context. Further we should make clear that we need to identify the real cause of an adverse event but not an mere symptom experienced at a remote host. This directly leads to the need of distributing the correct information to nodes which might be effected by the adverse event.
S3. Remediate
The third step is to remediate the effects of the adverse event or condition to minimise the impact. The goal is to do the best possible at all levels after an adverse event and during an adverse condition. Corrective action must be taken at all levels to minimise the impact of service failure, including correct operation with graceful degradation of performance.
Tasks
Distributed Decision Making
As soon as a failure has been detected a diagnosis process is started to find the root cause of the problem. This diagnosis process correlates all events which have been triggered by this failure on different instances in the system. This decision making will be distributed over all systems affected directly or indirectly by the failure. Depending on the effect of the system's operational state the remediation stage has to decide where to start which mechanism to remove the fault from the system or how to countervail the symptoms of the failure.
There may be a set of strategies available, to individual systems and consequently to the network as a whole, which can be used to (re-)enable communication given a particular failure. These strategies could be realised at different layers of the protocol stack, by different systems, and have a range of benefits and costs associated with them. Operating in a distributed system it must be guaranteed that the individual instances do not start contradicting mechanisms and thereby even worsen the system's operation state but to cooperatively find the best solution for the whole system.
The decision will be based on the result of the diagnosis process, the system's operational context and knowledge the system gathered during past events. The diagnosis process provides information about the fault which has been triggered in the system and where. The symptoms caused by the fault are part of the system's operational context and can be access during decision making, too. The information about symptoms is important to the decision making because some remediation mechanisms might not be applicable in certain scenarios.
In order to build a stable system the decision process has to consider previous decisions it made. Thereby, oscillation between two or more states can be prevented.
Reconfigure
After the decision which actions to take is made the system has to be reconfigured. Again this has to be a coordinated distributed action.
Reconfiguration data must be stored to allow a proper recovery later.
Measure improvement
In order to evaluate if the taken actions are sufficient to bring the distributed system back to acceptable service, a measurement entity is needed. Such a measurement can be done implicitly or explicitly. The measurement component also has to check that other services are still able to offer their service in an acceptable way to the system.
From the measurements the system has to derive and store knowledge. This knowledge will be take into account during the next remediation stage and during the refinement stage. The acquired knowledge has to consists of the current context of the system, the detected challenge or failure including their parameters, the taken actions, and the determint improvement of the system's operation state.
Counter Attacks
If we experience service degradation due to an attack a counter attack to take out the attacker (if he can be identified) might be an option.
Related Principles
- P4. Metrics
- P5. Resource Tradeoffs
- P7. Multilevel Resilience
- P8. Translucency
- P15. Connectivity and Association
- P16. Context Awareness
- P17. Adaptability
Remarks
S4. Recover
The fourth step is to recover to original and normal operations, including control and management of the network.
Once an adverse event has ended or an adverse condition is removed, the network should recover from its remediation state to allow any degraded services return to normal performance and operation.
Tasks
Tasks seam to be the same as for remediate: distributed decision making, reconfiguration, measure and evaluate. All details above.
Examples of recovery
- deployment of replacement infrastructure after a natural disaster
- restoration of normal routes after termination of a DDoS attack or the end of a flash crowd
Remarks
Marcus: Do we always want to go back to normal operation mode? Is it not possible to keep the countermeasures active although the adverse event is over? Especially, if the taken countermeasures are light-weight and do not impose performance penalties this would make sense. But than we need to think about how to measure the impacts of the taken countermeasures.
S5. Diagnose
While it is not possible to directly detect faults, a system may be able to detect resultant errors within itself, or failures may be detected outside the system. It may be possible to diagnose the fault that was the root cause. This may result in an improved system design, and may affect recovery to a better state.
Tasks
Event distribution
Some events must be delivered to remote entities.
Distributed Event Correlation
The symptoms of a failure will be detected on one or more instances of the distributed systems because of the inter-dependencies of the services the system is comprised of. The diagnosis process has to correlate all events which are symptoms of a single failure. All affected instances must be involved in the subsequent remediation process to countervail the effects of the failure.
The biggest obstacle is to acquire the needed information. E.g TCP does not know anything of IP routers on the path. If it sees segment losses it has to start a path based search to find out where which failure occurred.
Refine diagnostic
Certain scenarios might required a sparse deployment of sensors in the network during normal operation. These sensors are not able to provide enough information to the diagnosis to find the root cause of the adverse condition but indicate a problem. The diagnosis process can then request the deployment of additional sensors in the system to acquire more information. This leads to a more precise diagnosis result.
Related Principles
Remarks
S6. Refine
The final aspect of the strategy is to refine behaviour for the future based on past D2R2 cycles. The goal is to learn and reflect on how the system has defended, detected, remediated, and recovered so that all of these can be improved to continuously increase the resilience of the network.
Tasks
Long term learning
All events which occurred during system operation enrich the knowledge of the system about challenging conditions and how to remediate in these situation. From this knowledge the system will learn and improve the system. Improvements include i.e. protocol stack re-compostion, changes to the defensive mechanisms, removal of unsuitable mechanisms.
Updates
Refinement can also be triggered by software or hardware updates. If diagnosis identifies a fault in a component and reports this to the developer an updated version can be released to the system. Such updates have to be integrated into the system and old version have to be removed from the system.
Related Principles
Remarks
Design