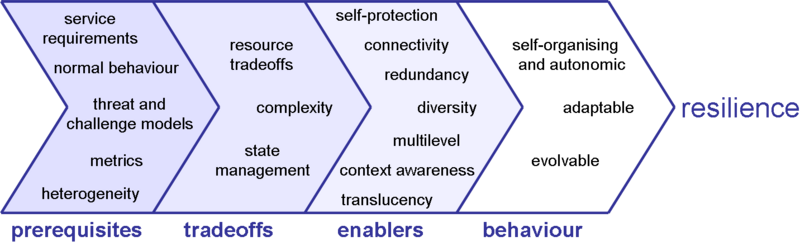
ResiliNets Principles
The ResiliNets Architecture is guided by a set of architectural principles, which support the ResiliNets Strategy D2R2+DR: defend, detect, remediate, recover, diagnose, refine, which in turn support the four ResiliNets Axioms IUER: inevitability, understand, expect, and respond. The principles are implemented by ResiliNets Mechanisms.
The target number of principles is O(10): large enough to provide specific guidance in the architecture and design of resilient networks, but small enough to be manageable without being overwhelming. Each principle is then applied to specific aspects of network architecture and design. For example, the principles of redundancy, diversity, and resource tradeoffs are refined and instantiated to the specific contexts of network architecture as
- fault tolerant network components (redundancy)
- spatially diverse redundant paths (redundancy and diversity)
- without replicating everything (resource tradeoffs).
Contents |
Prerequisites
P1. Service Requirements
Service requirements determine the need for network resilience
The user and application service requirements determine the necessary level and properties of resilience. In this sense, resilience and its subset survivability is an additional QoS property along with conventional properties such as performance. It is important to note that various applications demand different levels of resilience, and that some applications may not need networks that are highly resilient.
Application service resilience:
- ability to access information
- continuity of communication association
- service of networked storage and distributed processing
Relationship with other principles:
- specifies the requirements for P4. Metrics
- determines the resistance to P3. Threat and Challenge Models
P2. Normal Behaviour
Normal behaviour must be specified, verified, and refined through monitoring to understand normal operations
In order to understand normal operations and thus be able to detect adverse events or conditions, it is essential to understand the normal behaviour of the system. This involves several phases:
- Rigorous specification of system protocol and design, along with constraints in behaviour
- Functional verification of design
- Monitoring and learning normal behaviour of the system in situ
- Refinement of behaviour specification and operational constraints based on observation and learning of in situ operation
The refinement step is essential since existing systems have neither complete nor correct specifications, and the inherent complexity of networks challenges the ability to correctly specify such systems a priori
Relationship with other principles:
P3. Threat and Challenge Models
Threat and Challenge Models are essential to understanding and detecting potential adverse events and conditions
It is not possible to understand, define, and implement mechanisms for resilience that defend against, detect, and remediate challenges without a model of the threat.
Relationship with other principles:
- P1. Service Requirements
- P4. Metrics
- P9. Heterogeneity in Mechanism, Trust and Policy
- P13. Security and Self-Protection
P4. Metrics
Metrics are needed to measure and engineer network resilience
Metrics are needed to understand, analyse, evaluate, and engineer network resilience (and survivability). Furthermore, metrics are needed to understand the impact of an adverse event or condition on the network service provided.
Relationship with other principles:
- determines the satisfaction of P1. Service Requirements
- measures the impact of P3. Threat and Challenge Models
P5. Heterogeneity in Mechanism, Trust, and Policy
Heterogeneity in mechanism, trust, and policy among different network realms is a reality of emerging multi-provider networks; resilient mechanisms must admit this heterogeneity
It is increasingly unrealistic to consider the set of global networks (including the global Internet, PSTN, and domain-specific stovepipes) as a homogeneous internet. Rather the network becomes a collection of realms or compartments, which each have their own mechanism (addressing, forwarding, routing, signalling, traffic and resource management), and which define trust and policy relationships with one another. Social, political, economic, and regulatory concerns are manifest at these boundaries as tussle.
Network resilience is impacted in two ways:
- The resilience architecture and mechanism must admit this heterogeneity. Some of these issues result from the legacy PSTN (IXC/ILEC/CLEC) and Internet (AS/peering/tiers) architecture.
- Resilience depends on well-defined relationships among entities that need trust and policy boundaries. Thus resilience can exploit these relationships.
Examples:
- traditional wired Internet
- optical circuit-switched networks
- mobile infrastructure (cellular) networks
- mobile ad hoc networks
- sensor networks
Relationship with other principles:
Tradeoffs
P6. Resource Tradeoffs
Resource tradeoffs determine the deployment of resilience mechanisms
Networks are collections of resources that are not infinitely abundant.
P – processing
M – memory
B – bandwidth (rate)
E – energy and power
L – latency
£$€F¥ – cost
The relative composition and placement of these resources must be balanced to optimise resilience and cost. The maximum availability of a particular resource serves as a constraint in these optimisations.
Relationship with other principles:
- determines the relative application of other principles that have some resource cost. For example P9. Redundancy and P10. Diversity both require additional resource. In the limit, an infinite degree of both redundancy and diversity could maximise resilience, but this is clearly not practical. Determines the distribution among P7. Multilevel Resilience.
P7. Complexity
Complexity of the network in general, and resilience in particular, must be reduced to maximise overall resilience
Networks are inherently complex systems of systems, with interactions at multiple levels of hardware and software [Sterbenz-Touch-2001]. While many of the resilience principles and mechanisms increase this complexity, complexity itself makes systems difficult to understand and threatens resilience. The degree of complexity must be carefully balanced in terms of cost vs. benefit, and unnecessary complexity should eliminated.
Relationship with other principles:
- P1. Service Requirements
- P3. Threat and Challenge Models
- P4. Metrics
- P5. Resource Tradeoffs
- P12. Self-Organising and Autonomic
P8. State Management
State management is an essential aspect of networks in general, and resilience mechanisms in particular; the alternatives of how to distribute and manage this state are critical to resilience
State management is an essential part of any large complex system and is related to resilience in two ways:
- The resilience of the network is impacted by the way state is managed and the choices that are made:
- stateless vs. soft state vs. hard state
- distributed vs. mirrored vs. centralised
- tolerance of inconsistent vs. requirement for consistent
Resilience tends to favour the set of choices in bold, but these are choices that must be carefully made in the larger context of the overall system architecture.
- Resilience mechanisms themselves require state and it is important that they achieve their goal in increasing overall resilience by the way in which they manage state.
This principle is used to make a choice in mechanism.
Relationship with other principles:
- P5. Resource Tradeoffs
- P6. Complexity
- P10. Redundancy
- P12. Self-Organising and Autonomic
- P16. Context-Awareness
Enablers
P9. Security and Self-Protection
Security and self-protection are essential properties of entities to defend against challenges in a resilient network
The resilience of the network is dependent on the ability for entities to protect and defend themselves against challenges. Self-protection is implemented by a number of mechanisms, including but not limited to mutual suspicion, the AAA mechanisms of
as well as the additional conventional security mechanisms of
Relationship with other principles:
- P3. Threat and Challenge Models
- P9. Heterogeneity in Mechanism, Trust, and Policy
- P12. Self-Organising and Autonomic
- P16. Context-Awareness
P10. Connectivity and Association
Connectivity and association among communicating entities should be maintained when possible, but information flow should still take place even when a stable end-to-end path does not exit
Network connectivity should be maintained when practical, so that conventional communication mechanisms can be used based on eventual stability, which rely on information flow along a stable end-to-end path to maximise performance (minimise delay and memory).
When a stable end-to-end path is not possible, information can still flow as far as possible, whenever possible, based on the eventual connectivity model. Nodes store-and-forward when necessary, and may exploit mobility when nodes store-and-haul information or move into communication range to restore connectivity.
Relationship with other principles:
- P5. Resource Tradeoffs determine the feasibility of maintaining connectivity (e.g. transmission energy required to overcome noise) vs. alternate mechanisms.
P11. Redundancy
Redundancy in space and time increases resilience against faults and some challenges
Redundancy refers to the replication of entities in the network, generally to provide fault-tolerance. In the case that a fault disables part of a system, the redundant parts are able to operate and prevent a service failure.
Redundancy can be further categorised in two ways:
- degree (k-redundant)
- type (hot spare, active load balance, on-demand)
Spatial Redundancy
Replication of entities in space.
Examples:
- triple modular redundant hardware
- parallel links and network paths
Temporal Redundancy
Replication of entities in time.
Examples:
- erasure coding consisting of repeated transmission of packets
- periodic state synchronisation
- periodic information transfer (e.g. digital fountain)
Information Redundancy
The transmission or storage of redundant information.
Example:
- FEC (forward error correction) consisting of redundant bits
- erasure coding
Relationship with other principles:
P12. Diversity
Diversity in space, time, medium, and mechanism increases resilience against challenges to particular choices.
Diversity consists of providing different alternatives so that even when challenges impact particular alternatives, other alternatives prevent degradation from normal operations. The degree of diversity is the number of different alternatives. Diverse alternative can either be simultaneously operational, in which case they defend against challenges, or they may be available for use as needed to remediate.
Spatial Diversity
Diversity of an entity spread across space. Spatial diversity requires redundancy of a degree at least equal to the degree of diversity.
- Topological Diversity is spatial diversity across the (logical) topology of the network. Note that geographically diverse links and nodes may be topologically entwined.
- Geographic Diversity is spatial diversity across the physical topology of the network. Note that topologically diverse links or nodes may be physically co-located.
Spatial diversity examples:
- spatially diverse links
- spatially diverse nodes
Temporal Diversity
Diversity in the temporal behaviour of a component or protocol.
Temporal diversity example:
- variation in timing of protocol state transitions to resist traffic analysis
Operational Diversity
Operational diversity refers to alternatives in the architecture and implementation of network components and protocols.
- Implementation Diversity prohibits systems to exhibit the same error caused by an implementation fault.
- Medium Diversity provides choices among alternative physical mediums through which information can flow.
- Mechanism Diversity consists of providing alternative mechanisms.
Operational diversity examples:
- software from multiple vendors, such as operating systems on end systems and control of routers
- switches and routers from different hardware vendors
- fibre, free-space optical, RF – 802.11, 802.16
- open vs. closed loop – ARQ vs. FEC
Relationship with other principles:
- P1. Service Requirements
- P3. Threat and Challenge Models
- P6. Complexity
- P7. Multilevel Resilience
- P5. Resource Tradeoffs
- P10. Redundancy
- P14. State Management
- P15. Connectivity and Association
- P16. Context-Awareness
- P17. Adaptability
P13. Multilevel Resilience
Multilevel resilience is needed with respect to protocol layer, protocol plane, and hierarchical network organisation
An overall resilient system requires resilience at the various internal levels of its implementation. In the case of the global network, multilevel resilience is needed along three orthogonal dimensions:
- protocol layers: links, network paths, end-to-end transport, session control, applications
- we approach layers bottom up, that is each layer provides the best service practical given the cost of constrained resources, which provides a foundation for the next layer
- planes: data, control, and management
- network architecture: inside-out from fault tolerant components, through survivable subnetwork and network topologies, to the global Internetwork including attached end systems
Relationship with other principles:
- P1. Service Requirements
- P3. Threat and Challenge Models
- P4. Metrics
- P5. Resource Tradeoffs
- P6. Complexity
P14. Context Awareness
Context awareness is necessary for network components to operate autonomously to detect challenges
Context awareness is needed for resilient nodes to monitor the network environment (channel conditions, link state, operational state of network components, etc.) and detect adverse events or conditions.
Relationship with other principles:
- context awareness depends on P4. Metrics to measure and covey context
- context awareness is an essential requirement for P12. Self Organising and Autonomic
- context awareness is one of the inputs used for P17. Adaptability
P15. Translucency
Translucency is needed to control the degree of abstraction vs. the visibility between levels
Complex systems are structured into multiple levels to abstract complexity and separate concerns. In the case of networks this consists of three multilevel dimensions: layer, plane, and system organisation. While this abstraction is important, an opaque level boundary can hide too much and result in suboptimal and improper behaviour based on incorrect implicit assumptions about the adjacent level. Thus it is important that level boundaries be translucent in which cross-layer control loops allow selected state to be explicitly visible across levels.
- dials expose state and behaviour from below
- knobs influence behaviour from above
Relationship with other principles:
- P1. Service Requirements
- P4. Metrics
- P5. Resource Tradeoffs
- P6. Complexity
- P7. Multilevel Resilience
- P14. State Management
- P16. Context-Awareness
- P17. Adaptability
Behaviour
P16. Self-Organising and Autonomic
Self-organising and autonomic behaviour is necessary for network resilience that is highly reactive with minimal human intervention
A resilient network must initialise and operate itself with minimal human configuration, management, and intervention. Ideally human intervention should be limited to that desired based on high-level operational policy. The phases of autonomic networking consist of:
- initialisation – auto-configuration of network components and their self-organisation into a network
- steady-state normal operation – self-managing with minimal human interaction dictated by policy and self-optimising to dynamic network conditions
- steady-state expecting faults and challenges – self-diagnosing and self-repair
Relationship with other principles:
- P3. Threat and Challenge Models
- P5. Resource Tradeoffs
- P6. Complexity
- P7. Multilevel Resilience
- P9. Heterogeneity in Mechanism, Trust, and Policy
- P13. Security and Self-Protection
- P14. State Management
- P16. Context-Awareness
- P17. Adaptability
P17. Adaptability
Adaptability to the network environment is essential for a node in a resilient network to detect, remediate, and recover from challenges
Resilient network components need to adapt their behaviour based on dynamic network conditions, in particular to remediate from adverse events or conditions, as well as to recover to normal operations.
Relationship with other principles:
- adaptability is an essential requirement for P12. Self Organising and Autonomic
- adaptability is a short term reaction to P16. Context Awareness
- long term changes in the network operation and structure are covered by P18. Evolvability
P18. Evolvability
Evolvability is needed to refine future behaviour to improve the response to challenges, as well as for the network architecture and protocols to respond to emerging threats and application demands
Resilient network components should evolve their behaviour for two primary reasons:
- refinement of future behaviour based on reflection on the defence against, detection, and remediation of adverse events or conditions and recovery to normal operations
- evolution and extension of the network architecture and protocols over time, in response to long term changes in
- user and application service requirements, including new and emerging applications
- technology trends and resource tradeoffs
- changes in the communication environment
- attack strategies and threat models
Relationship with other principles:
- in cases that the network evolves itself, P12. Self Organising and Autonomic behaviour is required
- evolvability has a longer time constant and relatively larger scope than P17. Adaptability
© 2006–2010 James P.G. Sterbenz and David Hutchison