User:Mjs:Xlayer:Fmwrk
Contents |
Cross-Layer Sensing and Optimisations
The objective of a cross-layer architecture is to drive adaptation and optimisation of the interfacing between the user (application) and the network environment (i.e. the network-subsystem, be that a layered one, a monolithic one, or component-based one), so as to improve performance and stability. In that respect the (cross-layer) sensing and optimisation architecture supports and provides feedback for run-time functional composition and (re-)configuration.
The following figure shows a conceptual diagram of the functions a cross-layer architecture is required to be capable of performing.
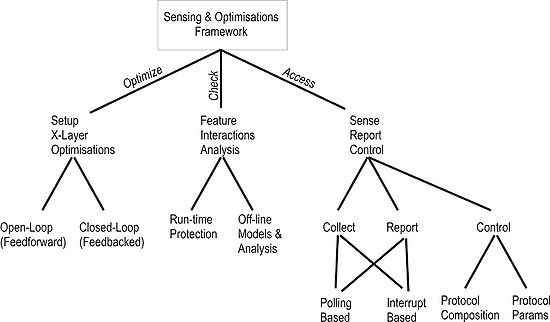
From a functional perspective a cross-layer framework should encompass 3 main capabilities denoted in the diagram by the three labelled main branches as “optimise”, “check” and “access”.
The “optimise” branch essentially refers to the enabling capability of the cross-layer/component optimisations. If such optimisations are modelled as typical control systems with input, processing/control functions and output then lending from control systems theory we are able to classify them in two distinct types, namely open-looped and close-looped. In open-loop optimisations the processing of the sensed input generates (or triggers) the optimised or optimising output action. Most cross-layer optimisations proposed in the literature so far are of this type flowing either upwards (sensing/input from a lower layer leads to optimisations in an upper layer – e.g. [HTLLS06]) or downwards (requirements input from an upper layer – application typically – lead to adapting a lower layer – e.g. [WCZS92]).
In feedback looped optimisations however, the optimised/ing output is fed back in conjunction with the input to further adapt the system and further adjust the output until stability is achieved by evaluating an error function. From a temporal aspect one can simply see the reinforcement of the output back to the input as a way of adding memory of past conditions to the optimised system while from a spatial perspective one can simply think of it as a self-correcting function.
The following figure illustrates a metaphor [ST01] for the two cases where by an open-looped optimisation has the form of a controlling knob between two layers, while the close-looped optimisation resembles the combination of a knob with a dial.
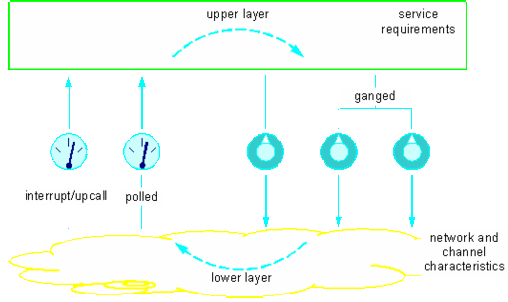
As part of the architecture, the (cross-layer/component) sensing and optimisations framework will provide an API through which an optimisation function will be able to register, set-up input/output hooks, and provide access credentials to the requested layer and measurement metrics. Typically such an optimisation function might be either internal to a micro-protocol FSM (e.g. as in TCP congestion control) and therefore in-band in the data path, or external to the data path (e.g. an external control/management component performing out-of-band configuration tasks).
The “check” branch involves mechanisms and tools that can be used to verify and check the correctness and conflict free feature interactions in the presence of multiple (cross-layer) optimizations. This is a particularly challenging issue and work area where there is not much research in the literature yet (apart from pointing out the problem [KK05]).
There are two types of checks taken into account in the framework. The on-line checks involve the employment of a plugin based interface through which “system health” protecting modules can be attached to the framework to safeguard for the system consistency in face of competing interactions either at instantiation time or at run-time (however similar interactions accounted in the compartment specification, off-line checks should be safely assumed). A functionality of one such prototype plugin is described briefly in the next subsection.
The off-line checks on the other hand involve the development of models, simulations and tools for checking and verifying correctness in face of feature interactions off-line before instantiation time. Although this aspect is considered integral in the overall cross-layer framework, however no actual run-time module is assumed.
The third and last branch labeled “access”, essentially refers to the capability of collecting information (sensing), reporting and controlling the various configurable aspects of the composition process. Collecting and reporting of information is assumed to in two possible ways. One is polling-based where by a shared memory space is used for storing and retrieving data (analogy of environment variables) asynchronously. The second mechanism is interrupt/notification based. A more synchronous operation is assumed in this model and the occurrence of an “interesting” event will trigger the activation of a set of registered callback functions that will multicast the “news” to the interested parties. A framework providing this functionality is presented in subsection "Cross-Layer Shareable Information Abstractions". The control capability refers to the access of the cross-layer module to the protocol composition (functional composition) and the protocol configuration (protocol tuning), which is implemented by means of respective configuration APIs that the cross-layer module has access to. A composable micro-protocol that has tuneable parameters is practically responsible for implementing such an API to enable the cross-layer module to access them. A mechanism enabling this functionality is presented in the subsection "Monitoring and Configuration Hooks".
Run time protection from undesirable feature interactions
Modelling the (cross-layer) optimisations as feedforward/back control systems enables us to use control systems theory and tools to study the issue of stability. In this section we consider a potential mechanism for safeguarding the healthy operation of an optimisation or protocol in a system independently of others in face of potential interactions with them, which is based on the modelling of a control system in the state space.
In control theory state space analysis is based on describing a system’s behaviour with a set of so called state variables. The state variables typically capture the input, output and internal state of a system at any moment in time. A set of equations, called state equations depict the dependencies between the state variables. Using the state equations and any current state of the system one is able to calculate what will be the next state of the systems given some discreet impulse signal. For computational simplicity the state variables and equations of a system can be represented using the so called state matrix.
Initially when modelling a control system (i.e. optimisation in our case) the challenge is the selection of good set of state variables that can sufficiently describe the system. Also this is quite crucial for the successful use of any of the stability test methods as well as for reducing the computational complexity of the state equations.
Once a set of suitable state variables has been determined, the stability of the system can be tested off-line either using simulations or using mathematical methods such as the Routh-Hurwitz criterion, the Nyquist criterion, and other. This off-line tests will also provide a range of acceptable values for the each of the state variables, for ensuring the systems stable operation.
At deployment time of the optimisation the set of state variables can provide heuristics for enforcing boundary conditions in the operation of the optimisation and warranty it is performing within the specification. The state variables would typically represent measurable/monitored of calculated metrics in the (cross-layer) sensing and optimisations framework (section 4.2.6.2). When an out-of-range value is detected for a state variable, an event can trigger some response action, which can be as simple as disabling the optimisation, enabling some quarantine condition, or as complex as taking some “healing” measures.
The state variables, their allowed value ranges and the low level information on which they depend as well as the response actions in case of instability, may be described as part of the optimisation specification.
Under the same thinking another possible approach would be to consider the whole network subsystem as a complex control system that needs to operate stably at all times. However the complexity of tracking all the interactions and determining suitable state variables, and deriving the state equations might prove to be particularly challenging.
To briefly exemplify the proposed mechanism we consider a case study from the literature [KK05] that illustrates a possible feature interaction. In this example a wireless ad-hoc network is assumed. The optimisation aims to provide optimal performance for TCP by adjusting the number of immediate neighbors seen, through tweaking the transmit power. This is done in two stages with two nested adaptation loops. In the inner loop, a node controls its transmit power so that the number of one-hop neighbors (out-degree) is driven to a parameter called target-degree. Transmit power is increased by one level if the number of one-hop neighbors is less than target-degree and decreased if it is greater than target-degree. An outer loop sets the value of the target-degree, based on the average end-to-end network throughput. The same action of the previous iterate is repeated if the network throughput increased from the previous iterate or it is reversed if the network throughput is decreased from the previous time step. If the network throughput is zero, the network is assumed to be disconnected and the target-degree is increased again. The outer loop is operated at a slower timescale than the inner loop to avoid the instability and incoherence that results from two simultaneous adaptation loops interacting with the same phenomenon, as elaborated on earlier. The outer loop therefore attempts to drive target-degree to a value that maximizes the end-to-end network throughput, and would therefore eventually drive the network out of any possible state of disconnection. To avoid getting in a complex analysis the following table simply outlines a set of possible state variables for this optimization, the source of information for its estimation and a description of the boundary conditions they enforce.
| State Variable | Information Source | Remarks |
|---|---|---|
| V1 (E2E Throughput) | TCP | Objective is that V1>0 at all times and max while the battery level drop rate does not exceed a max value |
| V2 (Target Degree) | Optimisation Config | Should not fall below a watermark |
| V3 (Out Degree) | Otimisation Config | Should not exceed of fall below watermark values |
| V4 (Power level) | H/W Batt status | Should not reduce at a higher rate than Max-Rate |
| V5 (Xmitt Power) | PHY | Should not increase above a Max value |
| V6 (Target Degree Updt Freq) | Optimisation Config | Should not flunctuate above a certain Max-Freq because it will lead to instability |
| V7 (Out Degree Updt Freq) | Optimisation Config | Used in calculations only |
An analysis and classification of different measurable metrics that we listed from the existing literature on cross-layer mechanisms, frameworks and optimisations, based on various heuristics, such as the information source (which layer), the type/form of the metric representation (scalar, Boolean, event, etc), the access type (read-only, or read-write as are protocol parameters), the dependence to a certain layer or micro-protocol, the scope (layer local versus across layers, and node local versus network wide), validity time, accuracy, and extrapolation approach (accounting, configuration state or inference assisted estimation) allowed us to draw the following conclusions:
- First of all the vast majority of the metrics as abstractions are micro-protocol specific and therefore reusable across layers as long as the respective FSM is present within a protocol layer.
- On the other hand the source of information of these metrics may differ depending on who is the interested party of that information. As a result for example congestion at the LL might be detected by seeing lots of collisions while congestion at the transport layer might be detected by looking at the combination of the timeout timer triggers (TCP timeout) and the (lack of) frame errors at the MAC level.
- There are a number of lower level metrics that can be grouped and “masked” under same higher level abstractions thus allowing a high-level generic abstraction to multiplex a combination of lower level metrics (as already exemplified in the aforementioned bullet point).
- Most of the metric information can be acquired using polling-based access or event-based hooks. However, in the case of event notifications a context needs usually to be provided as well with more detailed information.
- The format/type of the metrics fall in a small range of types that can be defined and provided as an attribute to assist in the retrieval and handling of the context information.
Based on these findings we extrapolated an initial set of requirements for the design of a flexible framework that will allow generic unified and flexible access to information from various parts of a network subsystem, and enable monitoring and optimisations:
- The framework should be flexible to facilitate polling based as well as interrupt (notifications based) access to monitor and configuration data.
- It should be possible for any entity to express interest in a set or combination of measurable low level metrics by means of an abstraction, and receive notifications and context information whenever the information is available
- It should be possible that a set of low level metrics are combined logically or otherwise under a higher level abstract metric and trigger a notification (to the interested parties) when the combining expression is evaluated to TRUE.
- Multiplexing of various combinations of low-level metrics under a higher level metric that is evaluated differently at different contexts (e.g. transport layer versus link layer) is a desired feature.
Starting from this requirements analysis we sketch out a framework for decoupling meta-information collection from its use, by cross-layer optimisation modules or other entities. This framework rests upon an event mechanism that uses high level metric abstractions to logically multiplex low level (raw) metrics and signal notifications to interested parties. Care is taken to enable information sharing among entities in an extensible way, and yet without restricting flexibility (that would be available if source and recipient of the information where directly communicating).
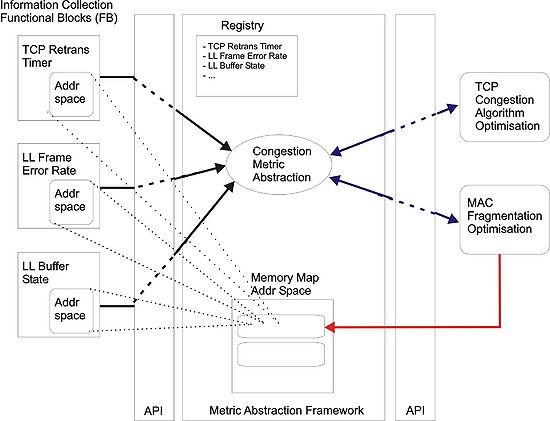
The figure illustrates the building blocks of this framework and exemplifies its functionality based on one such abstraction.
Looking at the figure from left to right one can see on the left the functional blocks that are responsible for providing the actual information represented by the low level (raw) metrics. Each such functional block makes known its existence through registration to a metrics registry as seen in the figure. At the right end (servicee/client side) of the figure one can see the entities which are interested in accessing the information provided by the raw metrics functional blocks. These entities maybe either cross-layer aware protocol engines, mediator modules that use the cross-layer information to tweek legacy protocol parameters and data structures, or other client modules (functional blocks) that are interested in the information. Inside the framework resides the raw metrics registry, the instantiations of the high level metric abstractions and the metric state/context memory, where detailed context information about the measured entities is made available.
The operation of the framework can be summarised as follows. All the functional blocks that are available for extracting metric information are registered with the framework. When a client entity comes that needs access to shared metric information it should be able to either provide a specification of the information it is interested in, or provide a higher level metric abstraction name. Given a specification of the high level metric abstraction, the framework instantiates the abstraction which essentially looks up in the registry for the associated raw metrics, “connects” to them by memory mapping their context address space to the metric context memory and optionally combines them logically using an event evaluation function that can trigger notifications to the client (if the client wants to have interrupt-based access to the information).
Note that in that respect the same high level metric abstraction can be used to service different clients by multiplexing different combinations of the same and new low level metrics. This provides thread/process economy through re-use. For example in the figure the metric abstraction named congestion is used to service a link-layer module and at the same time a transport (TCP) layer module by multiplexing information collected by 3 raw metric functional blocks (TCP timeout, link-layer error rate, and MAC-level queue state). A client module is notified of the memory mapped address space where the metric related context information is made available to it. If an event trigger function is generated for the serviced entity then a notification is sent whenever the event function evaluates to TRUE, through a callback mechanism by invoking a registered callback function. Alternatively, the client can poll in adhoc manner the metric context memory for changes and updates regarding the metric data.
The following figure shows the underlying “wiring” of event triggers for the scenario of the previous figure. It illustrates 5 different notifications encoded in the congestion abstraction multiplexing the three raw metric functional blocks. They can trigger different optimisations at the MAC layer or the TCP layer according to the following table. The notifications are sent to the two client modules in previous figure. The proposed optimisations are taken from the literature and are described in [?][?].
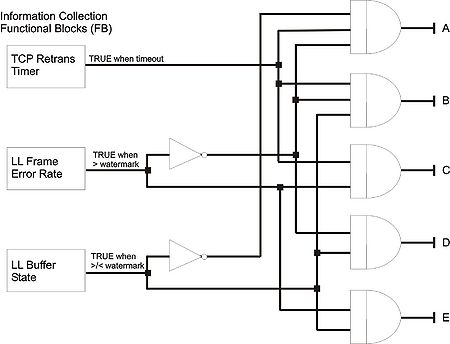
| TCP Retrans Timer | LL Frame Error Rate | LL Buffer State | Signal | Interpretation – Action |
|---|---|---|---|---|
| TRUE | FALSE | FALSE | A | Congestion in the network (e2e path). Enable TCP congestion algorithm and possibly do resource reservation. |
| TRUE | FALSE | TRUE | B | Congestion at the immediate next hop. Enable congestion relaxation at the MAC layer |
| TRUE | TRUE | X | C | Errors at the LL. Freeze congestion control at the TCP level []. Change fragmentation scheme at LL |
| X | FALSE | TRUE | D | Congestion at the LL. Enable channel reallocation |
| X | TRUE | TRUE | E | Errors due to interference at the LL. Change MAC fragmentation scheme |
Monitoring and Configuration Hooks
As our main objective is towards engineering mechanisms for collecting information and performing measurements, rather than proposing new measurement techniques, we need to consider what techniques are already available and identify their deployment requirements/limitations.
There are three different ways of producing the shareable information required for the raw metrics, i.e. by inference/estimation, through accounting, and by accessing fixed state (configuration or other stored state, e.g. connection state).
The latter type of information is probably the easiest one to collect as it is usually maintained in database storage, configuration files, or persistent memory that can be easily accessed locally or remotely (often through some existing API available).
The former two on the other hand are more difficult to acquire as there is often need for establishing some sort of measurement or monitoring (software or hardware) infrastructure either in-band or out-of-band in the data path. To this end it largely simplifies the problem analysis, allowing for generalised model, if we think in terms of functional blocks and perceive the problem as one where we have to perform measurements in a network of functional blocks (whereby a physical network interconnect is simply one possibility and a set of interconnected software functions –in a layered or other fashion- as in a node-OS network subsystem is simply another). In that respect the problem can be reduced to either acquiring running or configuration state resident within the functional blocks (through some common monitoring API) or carrying out measurements on the communication between functional blocks.
From the available literature we can identify three main approaches of carrying out measurements in a network: (a) active measurements where by one needs to introduce probing traffic for measuring certain characteristics; (b) passive measurements, where by one needs to set up monitoring functions at different points of interest in the network and seamlessly extract the useful information from the traffic passing through, then cross-correlate the measurements from the various points and estimate the metrics if interest; and finally (c) in-line measurements, by means of which, one can perform semi-active measurements at different aggregation levels and in a non-intrusive way. In-line measurements are based on the principle of either piggybacking or inserting measurement-carrying fields in-lined in packet data, which get processed at various points in-side the network.
These three different approaches of carrying out network measurements enforce to some extent the bounding requirements of our design space. In general it should be possible to introduce functional blocks (often seamlessly by means of the packet dispatch points) in an ANA compartment that can perform the following functions
- Insert, remove and process measurement data in-lined in data traffic.
- Generate probing traffic addressed to other functional blocks.
- Collect out-of-band, aggregate and process measurement data from various points in the network.
- Access other functional blocks and monitor their running state or access their configuration state.
Looking at bullet points 1 and 3 it becomes apparent that quite often in order to provide or generate the raw metric information required, a composite of cooperating measurement functional blocks (as opposed to a single one) will need to be deployed altogether. This is particularly true for cases where the metric data are generated as a result of cross-correlating (and processing) data collected from multiple network points, or cases where differentiating between two or more network points is required to extract the metric information. This imposes the additional requirement that
- Composition, cooperation and potentially synchronisation (out-of-band signalling) among measurement functional blocks across the network is a desired feature.
A collaboration with Fokus under the auspices of the Autonomic Network Architecture (ANA) project has resulted in a proposed framework for enabling this exact functionality prescribed here, which can be accessed in a forthcoming deliverable of the project.