Fault Tolerance
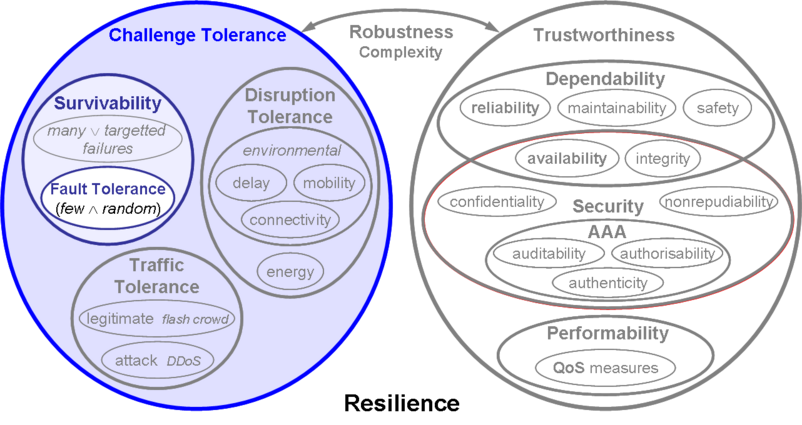
Fault tolerance is the ability of a system to tolerate faults such that service failures do not result. Fault tolerance generally covers single or at most a few random faults, and is thus a subset of survivability, as well as of resilience. [Resilinets]
[Moore-Shannon-1956 (doi) .]
E. F. Moore and Claude E. Shannon,
“Reliable Circuits using Less Reliable Relays”,
Journal of the Franklin Institute,
“Part I: Introduction”,
September 1956, pp. 191–208,
“Part II: The Central Problem”,
Journal of the Franklin Institute, vol.262, #3, Sep. 1956, pp. 191–208.
ResiliNets Keywords: fault-tolerance, reliability
Abstract: “An investigation is made of relays whose reliability can be described in simple terms by means of probabilities. It is shown that by using a sufficiently large number of these relays in the proper manner, circuits can be built which are arbitrarily reliable, regardless of how unreliable the original relays are. Various proerties of these circuits are elucidated.”
Notes: The seminal paper on fault-tolerance.
[Pierce-1965]
William H. Pierce,
Failure-Tolerant Computer Design,
Academic Press, New York, 1965
[Avizienis-1967 (doi) .]
Algirdas Avižienis,
“Design of Fault-Tolerant Computers”,
Proceedings of the Fall Joint Computer Conference (FJCC),
American Federation of Information Processing Societies (AFIPS), 1967, pp. 733–743
ResiliNets Keywords: list
Keywords: list from paper
Abstract: "full or partial abstract from paper"
Notes: (optional) relevance or importance or importance to ResiliNets
[Avizienis-1975 (doi) .]
Algirdas Avižienis,
“Fault-Tolerance and Fault-Intolerance: Complementary Approaches to Reliable Computing”,
ACM SIGPLAN Notices, vol.10, #6 1975
ResiliNets Keywords:
Keywords: Fault Tolerance, Fault Intolerance, Protective redundancy, reliable computing, redundancy techniques.
Abstract: “Two complementary methods which are employed in order to assure reliable computing are fault-intolerance and fault-tolerance. Fault-intolerance depends on the elimination of the causes of unreliability prior to the start of the computing process while fault-tolerance employs protective redundancy during the computing process in order to detect and to correct unreliable functioning. A balanced allocation of reliability resources between the two methods appears to offer the best practical solution. The paper reviews current fault-tolerance practices in system architecture and discusses their relevance to software systems.”
Notes: (optional)
[Avizienis-1983 .]
Algirdas Avižienis,
“Framework for a taxonomy of fault-tolerance attributes in computer systems”,
Proceedings of the 10th annual international symposium on Computer architecture, 1983, pp. 16-21
ResiliNets Keywords:
Keywords: Fault Tolerance.
Abstract: “A conceptual framework is presented that relates various aspects of fault-tolerance in the context of system structure and architecture. Such a framework is an essential first step for the construction of a taxonomy of fault-tolerance. A design methodology for fault-tolerant systems is used as the means to identify and classify the major aspects of fault-tolerance: system pathology, fault detection and recovery algorithms, and methods of modeling and evaluation. A computing system is described in terms of four universes of observation and interpretation, ordered in the following sequence: physical, logic, information, and interface, or user's. The description is used to present a classification of faults, i.e., the causes of undesired behavior of computing systems.”
Notes: (optional)
[Randell-1975 .]
Brian Randell,
“System structure for software fault tolerance”,
Proceedings of the international conference on Reliable software, 1975, pp. 437-449
ResiliNets Keywords:
Keywords: Acceptance test, Alternate block, Checkpoint, Conversation, Error detection, Error recovery, Recovery block, Recursive cache.
Abstract: “The paper presents, and discusses the rationale behind, a method for structuring complex computing systems by the use of what we term “recovery blocks”, “conversations” and “fault-tolerant interfaces”. The aim is to facilitate the provision of dependable error detection and recovery facilities which can cope with errors caused by residual design inadequacies, particularly in the system software, rather than merely the occasional malfunctioning of hardware components. ”
Notes: (optional)
[Lamport-Shostak-Pease-1982 (doi) .]
Leslie Lamport, Robert Shostak, and Marshall Pease,
“The Byzantine Generals Problem”,
ACM Transactions on Programming Languages and Systems (TOPLAS),
vol.4, #3, July 1982, pp. 382–401
ResiliNets Keywords: Byzantine fault-tolerance, reliability
Keywords: network operating systems, network communications, fault tolerance, reliability, algorithms, interactive consistency
Abstract: “Reliable computer systems must handle malfunctioning components that give conflicting information to different parts of the system. This situation can be expressed abstractly in terms of a group of generals of the Byzantine army camped with their troops around an enemy city. Communicating only by messenger, the generals must agree upon a common battle plan. However, one or more of them may be traitors who will try to confuse the others. The problem is to find an algorithm to ensure that the loyal generals will reach agreement. It is shown that, using only oral messages, this problem is solvable if and only if more than two-thirds of the generals are loyal; so a single traitor can confound two loyal generals. With unforgeable written messages, the problem is solvable for any number of generals and possible traitors. Applications of the solutions to reliable computer systems are then discussed.”
Notes: Defines a new concern for the field of fault tolerance in which components exhibit inconsistent behavior, perhaps maliciously.
[Avizienis-Kelly-1984 (doi) .]
A. Avizienis, and J.P.J. Kelly,
“Fault Tolerance by Design Diversity: Concepts and Experiments”,
IEEE Computer, vol.17, #8, Aug. 1984, pp. 67–80
ResiliNets Keywords:
Keywords:
Abstract: “”
Notes:
[Avizienis-1997 (doi) .]
A. Avizienis,
“Toward Systematic Design of Fault-Tolerant Sytems”,
IEEE Computer, vol.30, #4, April 1997, pp. 51–58
ResiliNets Keywords:
Keywords: fault tolerant computing, microprocessor chips, technological forecasting, chip manufacturers, competitive price, computing speed, critical applications, fault-tolerant microprocessors, fault-tolerant systems, high-confidence computing, quality of life, systematic design, ubiquitous computing
Abstract: “After 30 years of study and practice in fault tolerance, high-confidence computing remains a costly privilege of several critical applications. It is time to explore ways to deliver high-confidence computing to all users. The speed of computing will ultimately be limited by the laws of physics, but the demand for affordable high-confidence computing will continue as long as people use computers to enhance the quality of their lives. Eventually, one enterprising chip builder will deliver the first fault-tolerant microprocessor at a competitive price, and soon thereafter fault tolerance will be considered as indispensable to computers as immunity is to humans. The remaining manufacturers will follow suit or go the way of the dinosaurs. Once again, Darwin will be proven right ”
Notes:
[Somani-Vaidya-1997 (doi) .]
A.K. Somani, and N.H. Vaidya,
“Understanding Fault Tolerance And Reliability”,
IEEE Computer, vol.30, #4, April 1997, pp. 45–50
ResiliNets Keywords:
Keywords:
Abstract: “”
Notes:
[Schlichting-Schneider-1983 (doi) .]
Richard D. Schlichting,, Fred B. Schneider,
“Fail-stop processors: An approach to designing fault-tolerant distributed computing systems”,
ACM Transactions on Computer Systems, vol.1, #3, Aug. 1983, pp. 222–238
ResiliNets Keywords: list
Keywords: Reliability, Verification
Abstract: “A methodology that facilitates the design of fault-tolerant computing systems is presented. It is based on the notion of a failstop processor. Such a processor automatically halts in response to any internal failure and does so before the effects of that failure become visible. The problem of implementing processors that, with high probability, behave like fail-stop processors is addressed. Axiomatic program verification techniques are described for use in developing provably correct programs for failstop processors. The design of a process control system illustrates the use of our methodology.”
Notes: (optional) relevance or importance or importance to ResiliNets
[Birman-Joseph 1987 (doi) .]
Kenneth P. Birman and Thomas A. Joseph,
“Reliable Communication in the Presence of Failures”,
ACM Transactions on Computer Systems, vol.5, #1, Feb. 1987, pp. 47-76
ResiliNets Keywords: Fault-Tolerance, Reliability
Keywords: Concurrency; synchronization, network communication, reliability, :fault-tolerance, recovery and restart, distributed databases
Abstract: “The design and correctness of a communication facility for a distributed computer system are reported on. The facility provides support for fault-tolerant process groups in the form of a family of reliable multicast protocols that can be used in both local- and wide-area networks. These protocols attain high levels of concurrency, while respecting application-specific delivery ordering constraints, and have varying cost and performance that depend on the degree of ordering desired. In particular, a protocol that enforces causal delivery orderings is introduced and shown to be a valuable alternative to conventional asynchronous communication protocols. The facility also ensures that the processes belonging to a fault-tolerant process group will observe consistent orderings of events affecting the group as a whole, including process failures, recoveries, migration, and dynamic changes to group properties like member rankings. A review of several uses for the protocols in the ISIS system, which supports fault-tolerant resilient objects and bulletin boards, illustrates the significant simplification of higher level algorithms made possible by our approach.”
Notes: (optional)
[Lee-Anderson-1990 (doi) .]
P.A. Lee, T. Anderson,
“Fault Tolerance - Principles and Practice”,
Springer-Verlag Wien, 1990, ISBN 3-211-82077-9,
ResiliNets Keywords: list
Keywords: list from paper
Abstract: “full or partial abstract from paper”
Notes: (optional) relevance or importance or importance to ResiliNets
[Laprie-1995 .]
J.C. Laprie,
“DEPENDABLE COMPUTING AND FAULT TOLERANCE : CONCEPTS AND TERMINOLOGY”,
Twenty-Fifth International Symposium on Fault-Tolerant Computing, June 1995, pp. 2–11
ResiliNets Keywords: Fault-Tolerance
Keywords:
Abstract: “This paper provides a conceptual framework for expressing the attributes of what constitutes dependable and reliable computing: the impairrnents to dependability: faults, errors, and failures, the means for dependability: fault-avoidance, fault-tolerance, enor-removal, and error the measures of dependability: reliability, availability, maintainability, and safety. Emphasis is being put on the dependability impairments and on fault-tolerance.”
Notes:
[Chen-Avizienis-1995 .]
L. Chen and A. Avizienis,
“N-VERSION PROGRAMMINC: A FAULT-TOLERANCE APPROACH TO RELlABlLlTY OF SOFTWARE OPERATlON”,
Twenty-Fifth International Symposium on Fault-Tolerant Computing, June 1995, pp. 113–119
ResiliNets Keywords: Fault-Tolerance
Keywords:
Abstract: “N-version programing is defined as the independent generation of N>=2 functionally equivalent programs from the same initial specification. A methodology of N-version programing has been devised and three types of special mechanisms have been identified that are needed to coordinate the execution of an N-version software unit and to compare the correspondent results generated by each version. Two experiments have been conducted to test the feasibility of N-version programing. The results of these experiments are discussed. In addition, constraints are identified that must be met for effective application of N-version programing.”
Notes:
[Lyons-Vanderkulk-1962 (doi).]
R. E. Lyons and W. Vanderkulk,
“The Use of Triple-Modular Redundancy to Improve Computer Reliability”,
IBM Journal of Research and Development, Vol 6, #2, 1962, pp. 200–209
ResiliNets Keywords: Fault-Tolerance
Keywords:
Abstract: “One of the proposed techniques for meeting the severe reliability requirements inherent in certain future computer applications is described. This technique involves the use of triple-modular redundancy, which is essentially the use of the two-out-of-three voting concept at a low level. Effects of imperfect voting circuitry and of various interconnections of logical elements are assessed. A hypothetical triple-modular redundant computer is subjected to a Monte Carlo program on the IBM 704, which simulates component failures. Reliability is thereby determined and compared with reliability obtained by analytical calculations based on simplifying assumptions.”
Notes:
[Arlat-Costes-Crouzet-Laprie-Powell-1993 (doi) .]
J. Arlat, A. Costes, Y. Crouzet, J.C. Laprie, and D. Powell,
“Fault Injection and Dependability Evaluation of Fault-Tolerant Systems”,
IEEE Transactions on Computers, vol.42, #8, Aug. 1993, pp. 913–923
ResiliNets Keywords:
Keywords: fault injection; dependability evaluation; fault-tolerant systems; fault tolerance process; fault occurrence process; test sequence; dependability measures; distributed fault-tolerant architecture; Esprit Delta-4 Project; distributed processing; fault tolerant computing.
Abstract: “This paper describe a dependability evaluation method based on fault injection that establishes the link between the experimental evaluation of the fault tolerance process and the fault occurrence process. The main characteristics of a fault injection test sequence aimed at evaluating the coverage of the fault tolerance process are presented. Emphasis is given to the derivation of experimental measures. The various steps by which the fault occurrence and fault tolerance processes are combined to evaluate dependability measures are identified and their interactions are analyzed. The method is illustrated by an application to the dependability evaluation of the distributed fault-tolerant architecture of the Esprit Delta-4 Project.”
Notes:
[Hsueh-Tsai-Iyer-1997 (doi) .]
M-C. Hsueh, T.K. Tsai, and R.K. Iyer
“Fault Injection Techniques and Tools”,
IEEE Computer, vol.30, #4, April 1997, pp. 75–82
ResiliNets Keywords:
Keywords: fault diagnosis, fault tolerant computing, reliability, system monitoring, accessible points, chip pins, computer systems dependability, cost, fault injection techniques, fault injection tools, hardware implementation, higher-level mechanisms, internal components, low-level error detection, masking mechanisms, perturbation overhead, software implementation, software-state level change
Abstract: “Fault injection is important to evaluating the dependability of computer systems. Researchers and engineers have created many novel methods to inject faults, which can be implemented in both hardware and software. The contrast between the hardware and software methods lies mainly in the fault injection points they can access, the cost and the level of perturbation. Hardware methods can inject faults into chip pins and internal components, such as combinational circuits and registers that are not software-addressable. On the other hand, software methods are convenient for directly producing changes at the software-state level. Thus, we use hardware methods to evaluate low-level error detection and masking mechanisms, and software methods to test higher level mechanisms. Software methods are less expensive, but they also incur a higher perturbation overhead because they execute software on the target system ”
Notes:
[Yu-Bastien-Johnson-2005 (doi) .]
Y. Yu, B. Bastien, and B.W. Johnson,
“A State of Research Review on Fault Injection Techniques and a Case Study”,
RAMS 2005, Jan. 2005, pp. 386–392
ResiliNets Keywords:
Keywords: CAD, design engineering, fault location, fault simulation, redundancy, Simics, computer systems, dependability validation technique, design automation tools, design complexity, design processes, design schedule, fault injection techniques, fault propagation, testing mechanisms, triple modular redundancy
Abstract: “”
Notes:
[Clark-Pradhan-1997 (doi) .]
J.A. Clark and D.K. Pradhan,
“Fault Injection: A Method for Validating Computer-System Dependability”,
IEEE Computer, vol.28, #6, June 1995, pp. 47–56
ResiliNets Keywords:
Keywords: fault tolerant computing, program verification, reliability, software fault tolerance, React, Reliable Architecture Characterization Tool, computer system dependability, computer-system dependability, fault injection, fault tolerant computer system, operational system, redundancy, reliable service
Abstract: “A fault tolerant computer system's dependability must be validated to ensure that its redundancy has been correctly implemented and the system will provide the desired level of reliable service. Fault injection-the deliberate insertion of faults into an operational system to determine its response offers an effective solution to this problem. We survey several fault injection studies and discuss tools such as React (Reliable Architecture Characterization Tool) that facilitate its application ”
Notes:
[Abbott-1990 (doi) .]
Russell J. Abbott,
“Resourceful Systems for Fault Tolerance, Reliability, and Safety”,
ACM Computing Surveys, vol.22, #1, Mar. 1990, pp. 35-68
ResiliNets Keywords:
Keywords: Fault Tolerance, Software Fault Tolerance, Reliability, Software Reliability, Safety, Software Safety
Abstract: “Above all, it is vital to recognize that completely guaranteed behavior is impossible and that there are inherent risks in relying on computer systems in critical environments. The unforeseen consequences are often the most disastrous [Neumann 1986].
Section 1 of this survey reviews the current state of the art of system reliability, safety, and fault tolerance. The emphasis is on the contribution of software to these areas. Section 2 reviews current approaches to software fault tolerance. It discusses why some of the assumptions underlying hardware fault tolerance do not hold for software. It argues that the current software fault tolerance techniques are more accurately thought of as delayed debugging than as fault tolerance. It goes on to show that in providing both backtracking and executable specifications, logic programming offers most of the tools currently used in software fault tolerance. Section 3 presents a generalization of the recovery block approach to software fault tolerance, called resourceful systems. Systems are resourceful if they are able to determine whether they have achieved their goals or, if not, to develop and carry out alternate plans. Section 3 develops an approach to designing resourceful systems based upon a functionally rich architecture and an explicit goal orientation.”
Notes: (optional)
[Christian-1991 (doi) .]
Flaviu Cristian,
“Understanding Fault-Tolerant Distributed Systems”,
Communications of the ACM, vol.34, #2, February 1991, pp. 56–78
ResiliNets Keywords: Fault-Tolerance, Terminologies
Keywords: Reliability, availability, and serviceability, fault-tolerance, distributed systems
Abstract: “We propose a small number of basic concepts that can be used to explain the architecture of fault-tolerant distributed systems and we discuss a list of architectural issues that we find useful to consider when designing or examining such systems. For each issue we present known solutions and design alternatives, we discuss their relative merits and we give examples of systems which adopt one approach or the other. The aim is to introduce some order in the complex discipline of designing and understanding fault-tolerant distributed systems. 1 1 Introduction Computing systems consist of a multitude of hardware and software components that are bound to fail eventually. In many systems, such component failures can lead to unanticipated, potentially disruptive failure behavior and to service unavailability. Some systems are designed to be fault-tolerant: they either exhibit a well-defined failure behavior when components fail or mask component failures to users, that is, continue t...”
Notes: Definition of failure classification, failure semantics, failure masking; examples
[Nelson-1990 (doi) .]
Victor P. Nelson,
“Fault-Tolerant Computing: Fundamental Concepts”,
IEEE Computer, vol.23, #7, July 1990, pp. 19–25
ResiliNets Keywords: Fault-Tolerance, Terminologies
Keywords: fault tolerant computing, correction, digital systems, error detection, errors, fault containment, fault-tolerant computing, hardware, masking, module replication, protocol, reconfiguration, repair, self-checking logic, system recovery, timing checks
Abstract: “The basic concepts of fault-tolerant computing are reviewed, focusing on hardware. Failures, faults, and errors in digital systems are examined, and measures of dependability, which dictate and evaluate fault-tolerance strategies for different classes of applications, are defined. The elements of fault-tolerance strategies are identified, and various strategies are reviewed. They are: error detection, masking, and correction; error detection and correction codes; self-checking logic; module replication for error detection and masking; protocol and timing checks; fault containment; reconfiguration and repair; and system recovery”
Notes:
[Laprie-Arlat-Beounes-Kanoun-1990 (doi) .]
Jean-Claude Laprie, Jean Arlat, Christian Béounes, and Karama Kanoun,
“Definition and Analysis of Hardware- and Software-Fault-Tolerant Architectures”,
IEEE Computer, vol.23, #7, July 1990, pp. 39–51
ResiliNets Keywords: Fault-Tolerance
Keywords: computer architecture, fault tolerant computing, cost issues, hardware-fault-tolerant architectures, software-fault-tolerant architectures
Abstract: “A structured definition of hardware- and software-fault-tolerant architectures is presented. Software-fault-tolerance methods are discussed, resulting in definitions for soft and solid faults. A soft software fault has a negligible likelihood or recurrence and is recoverable, whereas a solid software fault is recurrent under normal operations or cannot be recovered. A set of hardware- and software-fault-tolerant architectures is presented, and three of them are analyzed and evaluated. Architectures tolerating a single fault and architectures tolerating two consecutive faults are discussed separately. A sidebar addresses the cost issues related to software fault tolerance. The approach taken throughout is as general as possible, dealing with specific classes of faults or techniques only when necessary”
Notes:
[TorresPomales-2000 .]
Wilfredo Torres-Pomales,
Software Fault Tolerance: A Tutorial,
NASA Technical Report NASA/TM-2000-210616,
Langley Research Center, Oct. 2000
ResiliNets Keywords: Fault Tolerance, Reliability
Keywords: software engineering, software reliability, computer programming, computer programs, fault tolerance, applications programs (computers), software development tools, operating systems (computers), computer systems design, complex systems, component reliability, quality control
Abstract: “Because of our present inability to produce error-free software, software fault tolerance is and will continue to be an important consideration in software systems. The root cause of software design errors is the complexity of the systems. Compounding the problems in building correct software is the difficulty in assessing the correctness of software for highly complex systems. After a brief overview of the software development processes, we note how hard-to-detect design faults are likely to be introduced during development and how software faults tend to be state-dependent and activated by particular input sequences. Although component reliability is an important quality measure for system level analysis, software reliability is hard to characterize and the use of post-verification reliability estimates remains a controversial issue. For some applications software safety is more important than reliability, and fault tolerance techniques used in those applications are aimed at preventing catastrophes. Single version software fault tolerance techniques discussed include system structuring and closure, atomic actions, inline fault detection, exception handling, and others. Multiversion techniques are based on the assumption that software built differently should fail differently and thus, if one of the redundant versions fails, it is expected that at least one of the other versions will provide an acceptable output. Recovery blocks, N-version programming, and other multiversion techniques are reviewed.”
Notes:
[Gartner-1999 (doi) .]
F.C. Gartner,
“Fundamentals of Fault-Tolerant Distributed Computing in Asynchronous Environments”,
ACM Computing Surveys, vol.31, #1, March 1999, pp. 1–26
ResiliNets Keywords: Fault-Tolerance, Terminologies
Keywords: agreement problem, asynchronous system, consensus problem, failure correction, failure detection, fault models, fault tolerance, liveness, message passing, possibility detection, predicate detection, redundancy, safety
Abstract: “Fault tolerance in distributed computing is a wide area with a significant body of literature that is vastly diverse in methodology and terminology. This paper aims at structuring the area and thus guiding readers into this interesting field. We use a formal approach to define important terms like fault, fault tolerance, and redundancy. This leads to four distinct forms of fault tolerance and to two main phases in achieving them: detection and correction. We show that this can help to reveal inherently fundamental structures that contribute to understanding and unifying methods and terminology. By doing this, we survey many existing methodologies and discuss their relations. The underlying system model is the close-to-reality asynchronous message-passing model of distributed computing.”
Notes:
[Schneider-1990 (doi) .]
F.B. Schneider,
“Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial”,
ACM Computing Surveys, vol.22, #4, Dec. 1990, pp. 299–319
ResiliNets Keywords:
Keywords: Algorithms, Design, Performance, Reliability
Abstract: “The state machine approach is a general method for implementing fault-tolerant services in distributed systems. This paper reviews the approach and describes protocols for two different failure models—Byzantine and fail stop. Systems reconfiguration techniques for removing faulty components and integrating repaired components are also discussed.”
Notes:
[AbdElBarr-Zakir-Sait-Almulhem-2003 (doi) .]
M. Abd-El-Barr, A. Zakir, S. M. Sait, A. Almulhem
“Reliability and Fault Tolerance based Topological Optimization of Computer Networks - Part I: Enumerative Techniques”,
Proceedings of 2003 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, (PACRIM 2003),
location, Aug. 28-30 2003, pp. 732–735
ResiliNets Keywords: Fault Tolerance, Reliability
Keywords: Topological optimization of Networks, Fault Tolerance, Reliability, Enumerative Techniques, Spanning Trees, Computer Networks
Abstract: “Topological optimization of computer networks is concerned with the design of a network by selecting a subset of the available set of links such that the fault tolerance and reliability aspects are maximized while a cost constraint is met. A number of enumeration-based techniques were proposed to solve this problem. They are based on enumerating all possible paths (for terminal reliability) and all the spanning trees (for network reliability). Existing enumeration-based techniques for solving this network optimization problem ignore the fault-tolerance aspect in their solution. We consider fault tolerance to be an important network design aspect In this paper, we propose one algorithm for optimizing the terminal reliability and another for optimizing the network reliability while improving the fault tolerance aspects of the designed networks. Experimental results obtained from a set of randomly generated networks using the proposed algorithms are presented and compared to those obtained using existing techniques. It is shown that improving the fault tolerance of a network can be achieved while optimizing its reliability however at the expense of a reasonable increase in the overall cost of the network.”
Notes:
[Steinder-Sethi-2004 (doi) .]
Malgorzata Steinder and Adarshpal S. Sethi,
"A survey of fault localization techniques in computer networks",
Science of Computer Programming, vol. 53, #2, November 2004, pp. 165-194
ResiliNets Keywords: Fault diagnosis
Keywords: Fault localization, Event correlation, Root cause analysis
Abstract: “Fault localization, a central aspect of network fault management, is a process of deducing the exact source of a failure from a set of observed failure indications. It has been a focus of research activity since the advent of modern communication systems, which produced numerous fault localization techniques. However, as communication systems evolved becoming more complex and offering new capabilities, the requirements imposed on fault localization techniques have changed as well. It is fair to say that despite this research effort, fault localization in complex communication systems remains an open research problem. This paper discusses the challenges of fault localization in complex communication systems and presents an overview of solutions proposed in the course of the last ten years, while discussing their advantages and shortcomings. The survey is followed by the presentation of potential directions for future research in this area.”
Notes: Definitions, Strategy, Techniques
[Varshney-Malloy-2006 (doi) .]
Upkar Varshney and Alisha D. Malloy
“Multilevel Fault Tolerance in Infrastructure-oriented Wireless Networks: Framework and Performance Evaluation”,
International Journal Network Mgmt, vol.16, #5, Mar. 2006, pp. 351-374
ResiliNets Keywords:
Keywords:
Abstract: “Significant advances have been made in the design and implementation of dependable systems and networks over the last several years. However, many wireless networks have not been designed for highly dependable operation owing to network cost and complexity, and a lack of regulatory requirements on wireless service quality. One way to address this significant challenge is by introducing fault tolerance; however, very limited work has been done so far in the fault-tolerant design of wireless networks. In this paper, we address how to utilize fault tolerance in the design of infrastructure-oriented wireless networks. More specifically, an architectural design scheme is presented for multilevel fault tolerance using adaptable building blocks. The scheme utilizes ‘selective’ redundancy at component, link and block levels and a fault-tolerant architecture for interconnection of building blocks. The design scheme has been implemented in both analytical and simulation models. The detailed performance results show that fault tolerance at component, link, block, and interconnection levels can significantly improve the overall dependability performance. One interesting observation is that, to achieve highest dependability, fault tolerance at link, component or block level is not sufficient and must be combined with the interconnection level fault-tolerance.”
Notes: (optional)
[Bejerano-Rastogi-2006 (doi) .]
Yigal Bejerano, Rajeev Rastogi
“Robust Monitoring of Link Delays and Faults in IP Networks”,
IEEE/ACM Transactions on Networking, vol.14, #5, Oct. 2006, pp. 1092-1103
ResiliNets Keywords: fault, Detect
Keywords: Approximation algorithms, latency and fault monitoring, network failures, set cover problem.
Abstract: “In this paper, we develop failure-resilient techniques for monitoring link delays and faults in a Service Provider or Enterprise IP network. Our two-phased approach attempts to minimize both the monitoring infrastructure costs as well as the additional traffic due to probe messages. In the first phase, we compute the locations of a minimal set of monitoring stations such that all network links are covered, even in the presence of several link failures. Subsequently, in the second phase, we compute a minimal set of probe messages that are transmitted by the stations to measure link delays and isolate network faults. We show that both the station selection problem as well as the probe assignment problem are NP-hard. We then propose greedy approximation algorithms that achieve a logarithmic approximation factor for the station selection problem and a constant factor for the probe assignment problem. These approximation ratios are provably very close to the best possible bounds for any algorithm.”
Notes: (optional) relevance or importance or importance to ResiliNets
[Reddy-Govindan-Estrin-2000 (doi) .]
Anoop Reddy, Ramesh Govindan, Deborah Estrin
“Fault isolation in multicast trees”,
SIGCOMM '00 Proceedings of the conference on Applications, Technologies, Architectures, and Protocols for Computer Communication
Stockholm, Sweden, 2000
ResiliNets Keywords:
Keywords: Fault isolation.
Abstract: “Fault isolation has received little attention in the Internet research literature. We take a step towards addressing this deficiency, exploring robust and scalable techniques by which multicast receivers can (in some cases, approximately) locate the on-tree router responsible for a route change, or the link responsible for significant packet loss. A common property of our techniques is that receivers with overlapped paths coordinate to share the responsibility of monitoring paths to the source. Our techniques assume no additional path monitoring capability other than that provided by multicast traceroute (mtrace).”
Notes: (optional)